
티스토리 뷰
Intro
* 자연어처리 분야에서 사용하던 Transformer를 Vision 분야에 적용
* 본 논문은 이미지를 여러 패치로 나누어 패치 자체를 단어처럼 보며 CNN에 의존하지 않고, Classification 에 적용
* 데이터가 적은 경우 Resnet보다 성능이 떨어지나, 데이터가 충분한 경우에는 보다 높은 성능을 보임.
-> Inductive Bias가 부족하기 때문
Vision Transformer (ViT)
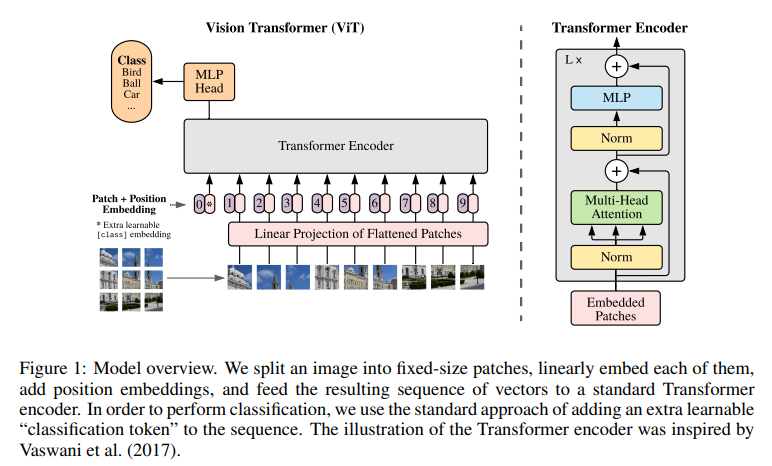
Transformer의 Encoder 부분을 응용하였다.
Embedding for Transformer
1. 2D 이미지를 1차원으로 변환하기 위해 Patch로 만들어준다.
ex) [300,300,3] -> [100,100,3]*9
2. 각 Patch를 Flatten 작업을 해서 D크기의 벡터로 만들어준다.
3. 각 벡터에 Linear 연산을 거쳐서 임베딩 하도록 해준다.
- 추가적으로 자연어 처리 분야에서 BERT라는 모델에서 사용되는 [Class] 토큰과 비슷하게 Input Embedding 맨 앞에 [Class] Patch를 넣어준다. -> 이후 Transformer Encoder의 출력() 중 맨 앞()에 대응되며, 이는 Classification Head(MLP Head)에 입력으로 들어가 Classification 작업에 사용된다.
- 최종적으로 각 Embedding된 Patch들이 Encoder에 들어가기 전에 학습 가능한 Position Embedding을 더하여 각 Patch Embedding들에 위치에 대한 정보를 추가해준다.
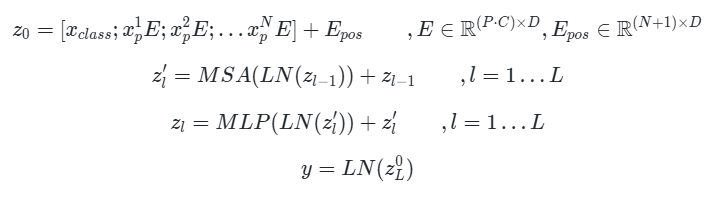
식으로 나타내면 이와 같다.
Inductive Bias
"유도 편향" -> 학습에 사용되지 않은 데이터에 대해서 어떤 것을 예측할 때 정확한 예측을 위해 사용하는 추가적인 가정이라고 볼 수 있다.
Transformer 에서는 Locality와 Translation Equivariance를 제시한다.
Translation Equivariance : 예를 들면, x -> x+t로 입력이 변할 시 f(x) -> f(x+t)로 출력도 동일하게 되는 것이다.
즉, 해당 객체의 위치가 달라져도 동일하게 검출할 수 있도록 하는 것이다.
Locality : 지역적인 특징을 뜻함. CNN에서는 여러 크기의 필터를 사용해 지역적인 정보를 담는다.
ViT는 이미지를 패치로 나누어 작동하고, 한 패치 내부에서만 Fully Connected 형식으로 작동한다.
이러한 이유로 CNN에 비해 Inductive bias가 더 적다고 할 수 있다. => 더 많은 data 필요!
Experiments


학습한 ViT를 기반으로 모델이 어디에 집중하는 지를 시각화한 것이다.
'AI > Classification' 카테고리의 다른 글
| [논문리뷰] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (0) | 2025.02.12 |
|---|---|
| CNN 아키텍쳐 비교(AlexNet, VGG, GoogleNet, Resnet, SENet) (0) | 2025.02.12 |
- Total
- Today
- Yesterday
- SQL
- 스테이블디퓨전
- 코테준비
- 프로그래머스
- 코랩에러
- 파이썬
- AIRUSH
- gan
- 파이썬코테
- AI컨퍼런스
- 컴퓨터비전
- 논문리뷰
- gs논문
- 드림부스
- Gaussian Splatting
- SKTECHSUMMIT
- 논문
- 테크서밋
- Aimers
- AIRUSH2023
- 3d-gs
- dreambooth
- 코딩공부
- 2d-gs
- 논문읽기
- CLOVAX
- lgaimers
- MYSQL
- Paper review
- C언어
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |